DNAコード化ライブラリー(DEL)の原理と導入ガイド
DNAコード化ライブラリー(DNA encoded library, 以下DEL)は、評価したい化合物それぞれに固有のDNAタグを付与し、数十億種規模のライブラリーを一括スクリーニングする手法です。
創薬において、シード化合物発見のためのスクリーニングは、その後の方向性を決定する重要な段階です。しかし、近年ではアプローチしやすい構造はほぼ掘り尽くされており、ケミカルスペースをさらに広く、深く探索する技術が求められています。このため、 ハイスループットスクリーニング(High-Throughput Screening ,以下HTS )、バーチャルスクリーニングなどさまざまなスクリーニング手法が開発されてきました。中でもDELは、数億もの化合物を一挙に評価できる点、使用するタンパク質が微量(µg単位)しかなくてもスクリーニングが可能な点で注目を集めています。
|
比較項目 |
HTS |
DEL |
デジタルスクリーニング |
|
ライブラリー規模 |
~10⁶(百万) |
~10¹²(数億~数兆) |
10⁶以上(DB依存) |
|
ヒットの指標 |
活性(機能アッセイ) |
結合(アフィニティ) |
予測スコア |
|
タンパク質消費 |
mg単位(多い) |
µg単位(少ない) |
不要 |
|
使用不可タンパク質 |
熱などに不安定なもの |
DNA結合性タンパク質 |
構造が変化しやすいタンパク質 |
|
アッセイ構築 |
必須(Z'-factor等) |
不要 |
不要 |
|
設備投資 |
大(ロボット等) |
小(PCR+NGS) |
小(PC+ソフトウェア) |
|
最適なフェーズ |
既存ライブラリーあり |
新規探索・難標的 |
初期スクリーニング |
これまでDELは、外部研究機関への委託が必要であり、コストや煩雑な契約などが問題でした。ただし最近では買い切り型DELキットなども登場しており、ぐっとハードルは低くなっています。
DELの基本原理――DNAバーコードで数十億の化合物を識別する(DNA-Encoded Library Screening)
DELという手法のポイントは、化合物を識別するための「タグ」として、ライブラリーの各化合物にDNA鎖を結合させておく点です。商品一つ一つに、情報を持ったバーコードをつけておくイメージです。
多種類の化合物を一挙に評価する際に問題になるのが、ヒットした化合物の識別です。タンパク質への結合の有無だけなら微量の化合物でも評価可能ですが、これを精製して構造決定を行うことはコスト的にも技術的にも困難です。
そこで、化合物の構造に対応させたDNAのタグを結合させておき、これを用いて構造を決める手法が開発されました。DNAはPCR法によって増幅することができ、配列の読み取り法も確立していますので、タグとして非常に有効なのです。
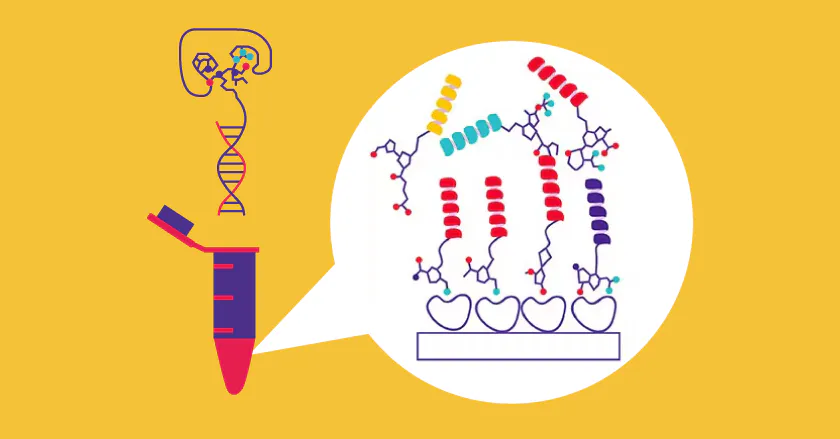
DELにもさまざまな手法が開発されていますが、ここではスプリット&プール法による、アミノ酸20種を用いたペプチド合成を例にとって解説しましょう。まず、ヘッドピースと呼ばれる化合物(短いDNA鎖に、リンカーを介してアミノ基が結合したもの)の溶液を、20等分に分けます。これらそれぞれに、タグとなる20種の短いDNA鎖を、DNAリガーゼによって結合させます。そしてアミノ基部分に、20種のFmocアミノ酸を縮合剤によって結合させます。これらそれぞれのDNA鎖とアミノ酸は、たとえばATGCATGCATGCはアラニンを意味するといったように、1対1に対応しています。
こうしてDNA鎖とアミノ酸が導入されたところで、いったん全ての溶液を混合し、再び20等分に分けます。これらそれぞれに、新たなDNA鎖20種の導入、Fmoc基脱保護、DNAタグの情報に対応したアミノ酸20種の導入を行います。これにより、20×20=400種のジペプチドが、対応するDNAタグに結合したものができます。
スプリット&プール法によるDNAコード化ライブラリー(DEL)の作製(山東らによるMEDCHEM NEWSの解説記事*1を元に作成)
このスプリット&プール操作を5回繰り返すと、205=32万種のペンタペプチドとDNAタグが結合したライブラリーができあがります。この混合溶液を、担体に固定した標的タンパク質に加えて親和性の高いペプチドだけを結合させ、他のペプチドは洗浄処理で除去します。得られたヒット化合物に結合しているタグのDNA部分を、PCR法で増幅させます。シークエンサーによってこの配列を読み取ることで、ヒットしたペプチドの構造を判別します。
DELの優位性と制約
DELはさまざまな面で優れたスクリーニング手法ですが、やはり制約もあります。まず優位性を挙げると、次のようになります。
(1)多様性
DELでは、数回の繰り返し操作を行うだけで、単一のバイアル内に数億種レベルのライブラリーを構築することが可能です。通常のライブラリーの場合、保管スペースや管理費用などが必要になりますが、DELでは不要です。極めてコンパクトに、今までのライブラリーより数桁多い化合物を一挙に作り出せる点は魅力です。
(2)AIとの適合性
最近では、こうして得られたデータをAIに学習させ、より高活性かつドラッグライクな構造を提案させるアプローチも盛んです。DELで得られる大量の化合物データは、AIにとって格好の教師データになりえます。
一方、制約もあります。
(1)合成反応の制約
DNAは水溶性ですので、ライブラリー作成に用いる反応は水中で進行するものでなければなりません。またDNAが破壊されない、温和な条件で進行することも必須です。このため、DEL構築に使用可能な合成反応はある程度限られます。
具体的には、アミドカップリング反応、鈴木-宮浦カップリング、Huisgen反応などの各種クリック反応、求核的芳香族置換反応などが利用可能です。
(2)評価段階における制約
DEL法で合成された化合物はDNAタグが結合した状態ですので、タグがない状態ではタンパク質との結合の仕方が変わる可能性があります。また、DELで測定できるのは結合能であり、標的タンパク質の機能を阻害するのか、アゴニストとして働くのかなどはわかりません。このため正確な活性を知るためには、ヒットした化合物は別途合成し直し、DNAのない状態でアッセイを行う必要があります。
(3)実務的な制約
DELの構築にはそれなりのノウハウが必要であるため、これまでは外部の研究機関に委託する形が主流でした。しかし高コストであり、煩雑な秘密保持契約も必要なので、敷居が高かったのも事実です。しかし最近になり、買い切りのDELキットも登場しました。これは外部委託に比べてずっと低コストであり、製薬企業はもちろんアカデミアの研究室でも導入可能です。当然、得られたデータは100%自社の資産となりますし、成功報酬や将来のロイヤリティなどの支払いも発生しません。DELとはどんなものなのか、一度試してみたいという方には、最も適した方法でしょう。
DEL導入ガイド――買い切り型キットで始めるスクリーニング
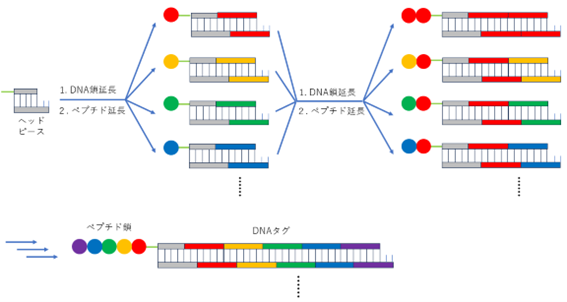
シグマアルドリッチから発売されているDELキットには、2種類のタイプがあります。一方は、フラグメント創薬の考え方を融合させた「DNAコード化フラグメントライブラリー」と呼ばれるタイプ(製品番号:DYNA001)です。もう一方は、約1000万化合物を含む、完成したタイプのライブラリー(製品番号:DYNA002)です。
DYNA001では、タンパク質に結合しうる小分子量のフラグメント(614種)に、一本鎖DNA部分と、タグとなる二本鎖DNAが連結したものが混合されています。これを溶解させると一本鎖部分がランダムにハイブリダイズし、2つのフラグメントが近接したペアが形成されます(6142=約37万種)。これをDEL法と同様にスクリーニングし、タンパク質に強く結合するフラグメントペアを選ぶというものです。比較的少数のフラグメントが二つ組み合わさることで、高いダイバーシティと偽陽性の低減を実現しています。
小分子量であるためヒット確率は向上しますが、2つのフラグメントの構造が判明したら、両者をリンカーでつないだ化合物を合成・最適化し、単一のヒット化合物に仕上げていく必要があります。
一方のDYNA002は、3つのビルディングブロックをアミド結合を介して結合させた、約1000万化合物から成るライブラリーです(下図参照)。こちらでは、広いケミカルスペースの探索が可能です。
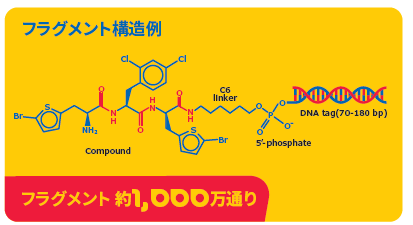
どちらのタイプも、特殊なノウハウを要するライブラリー合成は必要なく、タンパク質との結合試験を行い、ヒットした化合物群のDNA配列を決定するだけです。この配列データから、ヒット化合物の構造を知ることができます。
両タイプの比較
|
製品 |
DYNA001 |
DYNA002 |
|
タイプ |
フラグメントDELキット |
1,000万化合物DEL |
|
ライブラリー規模 |
37万種以上の |
3種のビルディングブロックの組み合わせ |
|
技術特徴 |
ダイナミックライブラリー技術 |
広範囲のケミカルスペース |
|
推奨用途 |
ターゲットのトラクタビリティ検証 |
本格的な |
|
ヒット手法 |
フラグメントの小サイズ化によってヒット率を向上 |
大きなサイズのライブラリによって化合物の |
|
研究ステージ |
フラグメント対を元に、開発作業が必要 |
ヒット化合物をそのまま開発することが可能 |
|
パッケージ |
5バイアル |
2バイアルもしくは5バイアル |
|
構造情報 |
ヒット構造のみ開示 |
全構造データを開示するプランあり |
各製品の技術背景やワークフローの詳細は「DNA Encoded-Library (DEL)を用いた創薬の発展」をご覧ください。
まとめ――DELで広がるリード化合物探索の可能性
DELは数億種の化合物を一挙に評価できるシステムとして極めて有用であり、使用が広がっています。本格的に取り組む際にはノウハウがある程度必要ですが、近年は手軽にアクセスできる買い切りのキットも入手可能です。フラグメントDELキットと通常のDELキットが入手可能ですが、まずはターゲットタンパク質のトラクタビリティを検証するため、前者のキットを利用してみるのも有効です。
DYNA001(DyNAbind® フラグメントDELキット)およびDYNA002(DyNAbind® 1,000万化合物DEL)の詳細・ご購入は、以下の製品ページをご覧ください。
・DYNA001:https://www.sigmaaldrich.com/JP/ja/product/sial/dyna001
・DYNA002:https://www.sigmaaldrich.com/JP/ja/product/sial/dyna002
DELスクリーニングの技術背景や製品の詳細については「DNA Encoded-Library (DEL)を用いた創薬の発展」もあわせてご覧ください。
DELに関する関連カタログはこちらをご覧ください。
FAQ: 導入に関するよくある質問
Q: DELを始めるのに秘密保持契約は必要ですか?
A: シグマアルドリッチのDELキットは通常の研究用試薬などと同様、カタログ品として購入可能です。事前のライセンス契約などは必要ありません。また、実験で得られたデータは購入者だけが閲覧できるものであるため、秘密保持契約も必要ありません。
Q: ヒット化合物の知財は誰に帰属しますか?
A: シグマアルドリッチのDELキットは買い切り型のため、発見したヒット化合物のデータは100%自社の資産になります。ヒットした際のロイヤリティも発生しません。このため、追加費用や特許の帰属問題などの心配はありません。
Q: DYNA001とDYNA002のどちらを選ぶべきですか?
A: まずターゲットのトラクタビリティを検証したい場合はDYNA001を選び、ヒットの確認を行うことが推奨されます。本格的な探索をしたい場合には、DYNA002で多数の化合物を手に入れ、スクリーニングを行うとよいでしょう。どちらも完成したライブラリーであり、有機合成などの技術は必要ありません。
各製品の選定ガイドやプロトコル情報は「フラグメントDELを用いた創薬研究」でも解説しています。
Q: どの程度のタンパク質が必要ですか?
A: DELキットの場合、1回のセレクションに必要なタンパク質は約40 µg程度です。キットには複数バイアルが含まれており、濃度条件を変えた実験やコントロール実験を含めても、合計200 µg程度で一通りのスクリーニングが実施可能です。HTSではmg単位のタンパク質が必要なので、これよりずっと少なく済みます。今まで大量のタンパク質が用意できず、研究を諦めていたようなケースでも、DELならスクリーニング可能です。
<参考文献>
*1) 植木亮介,山東信介 MEDCHEM NEWS 28, 93 (2018)
<DEL全般に関する総説>
- E. Kleiner et al., Chem. Soc. Rev., 40, 5707 (2011)
- A. Peterson & D. R. Liu Nature Drug Discovery, 22, 699 (2023)
DELスクリーニングについてのご相談・お問い合わせ
ターゲットに合った製品の選び方や、実験プロトコルの詳細など、DELスクリーニングの導入に関するご質問はお気軽にお問い合わせください。


下記フォームでは、M-hub(エムハブ)に対してのご意見、今後読んでみたい記事等のご要望を受け付けています。
メルクの各種キャンペーン、製品サポート、ご注文等に関するお問い合わせは下記リンク先にてお願いします。
*入力必須